JavaScript testing
This post about JavaScript testing is part of the Setting up a full stack for web testing series.
Introduction
JavaScript tests are sufficiently special to deserve a post outside of unit and functional testing. You need a special set of tools to write these tests. But then again for JavaScript the usual split between unit and functional tests is still applicable. So what I wrote about those two topics is also relevant here.
In this post I cover two separate tools for JavaScript testing: JsTestDriver, which is great for JavaScript unit tests, and Selenium which can be used to functional test a web application that uses JavaScript.
Selenium
Selenium is a software suite used to remotely control browsers. It consists of various sub-projects:
- Selenium Core: This is the original Selenium. It allows you to create a HTML page with some browser commands. Those commands can then be run in the browser when you open the page.
- Selenium IDE: A Firefox extension that can record your actions in the browser. This is a great way to learn the Selenium syntax as you can then export the recorded actions in several programming languages.
- Selenium Remote Control (Selenium RC): A Java server that allows controlling browsers remotely. Can be used from any programming language using a simple HTTP API.
- Selenium Grid: Basically the same as Selenium Remote Control but for running in parallel.
Personally I only use Selenium RC, so I won’t talk about the other parts. To get started, read the excellent Selenium documentation which explains everything a lot better than I could. If you want a quick start I recommend the Selenium RC chapter.
The basic test case in Selenium works like this:
- Open the page to test (with by first logging in)
- Execute some action like a click on a link or a mouse event
- Wait for the action to execute (Ajax loads to finish, etc.)
- Assert that the result is as expected
These four steps are repeated for every test case – so a lot of pages will be opened. Opening all those pages is the reason why Selenium tests tend to be very slow.
As a test framework you can use whatever you already have – in your favorite programming language. The difference is just that in your tests you will talk to Selenium to get the current state.
Take the following Python code as an example:
def test_login():
sel = selenium("localhost", 4444, "*firefox", "http://localhost:5000/")
sel.start()
sel.open("/login")
assert sel.is_text_present("Login")
assert sel.is_element_present("username")
assert sel.is_element_present("password")
assert sel.get_value("username") == 'Username'
This script launches a Firefox browser and opens a login page of an application running on the localhost. It then gets several values from Selenium and asserts the correctness of these values using the standard test framework methods.
JsTestDriver
JsTestDriver is a relatively new tool which can be used to submit tests suites to browsers. Those browsers have to register with a Java-based server and you execute tests by submitting them to that same server.
So far that sounds very similar to Selenium. The difference is that JsTestDriver works with a blank page in which it directly inserts the test suite. It does that with a lot of optimizations to make sure the test runs are as fast as possible.
After that the unit test suite is run – directly inside the browser – and the client gets the test results including stack traces if available.
I recommend the Getting started documentation on the JsTestDriver wiki to see some code.
One of the main differences to Selenium is that you write the tests directly in JavaScript. There is a built-in test framework but you can also use other frameworks depending on your taste.
To show some code that you can contrast with the Selenium example above, consider this example:
GreeterTest = TestCase("GreeterTest");
GreeterTest.prototype.testGreet = function() {
var greeter = new myapp.Greeter();
assertEquals(“Hello World!”, greeter.greet(“World”));
};
Differences
Selenium is a very magic piece of software. Everybody falls in love with it when seeing their browser doing all the work. It’s something people just can’t resist. And so they end up using Selenium for all their web testing needs. I’ve been there myself.
The downside of Selenium is that it’s very brittle and slow. This is something that can’t really be avoided because all it does is control a browser. Opening pages and waiting for all scripts to load takes some time. And doing that hundreds or thousands of times, as is easily the case in a large test suite, leads to very slow test executions.
So instead of falling into that trap and only using Selenium, I recommend to clearly separate out unit tests which you can then execute in JsTestDriver. JsTestDriver does a lot less work and because of that is a lot more stable and faster. Then do integration tests with Selenium to test some basic workflows.
As an example take an autocompletion widget which is used on a search home page. Almost everything the widget does you can test by just calling its public interfaces and seeing if it does the right thing. This includes all the strange edge cases such as handling network timeouts or invalid data. So this part you do with a big JsTestDriver test suite. Then you only need one small functional test case to make sure the widget is correctly embedded in your home page. That’s your Selenium test.
As is evident I’m very happy that JsTestDriver has come along. Before that the only good solution for JavaScript testing was Selenium – and as I explained above it’s not a perfect fit for every testing need.
Conclusion
If you have followed my testing tutorial so far you now have all your testing tools set up. Some more chapters will follow but those now cover testing philosophy and tools around the principal testing framework.
Pot: WSGI
This Python on the Toilet issue is also available as PDF.
WSGI is a Python standard for how web servers can interact with web frameworks. It’s one of my favorite standards: it’s simple yet very powerful.
To write a WSGI web application you only need to create one function.
def my_app(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return repr(environ)
The function receives a environ argument – a dictionary with all the environment variables. The start_response function can be called with the status line and a list of headers as soon as you’re ready to send output.
New Python releases contain the library wsgiref which can be used to get started quickly with a simple web server (that should not be used in production).
pre..from wsgiref.simple_server import make_server
httpd = make_server(‘’, 8000, my_app)
httpd.serve_forever()
Save these two snippets in a file e.g. myapp.py and execute it with Python. This will serve the sample application on port 8000. Try it out.
You don’t usually want to write your own application directly on top of WSGI. But most frameworks now implement WSGI which has led to better interoperability. If you still want to use WSGI directly, there are a ton of good tools such as WebOb?, “Werkzeug” or “Paste”. I used WebOb to easily build a REST service framework called WsgiService.
For more information I recommend the specification for WSGI which is a good read.
This post is part of the Python on the toilet series.
Functional testing
This post about unit testing is part of the Setting up a full stack for web testing series.
Introduction
In functional testing, also referred to system testing or blackbox testing, you don’t just test the individual units but the whole application. So you’re testing if all of the small units you built and tested actually work together.
For functional testing a web site I talk to the application in HTTP. As mentioned already in Unit testing, an example for an address book would be to create an address using the provided web form, then check that the detail page renders and that it shows up in a list or search result.
I explicitly exclude JavaScript tests from this category, as I’ll cover those later in a separate post. The reason I don’t include them in functional tests is that Javascript tests tend to be more fickle and I try to have as stable functional tests as possible.
Tools
For functional testing you should get a tool which allows you to test the HTTP and HTML part of your applications.
As with the generic testing framework this is something that your web framework probably already provides. So check your framework documentation, some pointers:
- Django
- Okapi
- Pylons (though they call it “unit testing” it’s what I refer to as functional testing)
- Ruby on Rails
If you’re outside of a framework there are still great tools that you can use:
- Java: HttpUnit
- PHP: SimpleTest Web tester
- Python: WebTest (works with any WSGI application)
I really like the simplicity of the WebTest solution and think that more such tools should be provided. HttpUnit seems to have the same capabilities (using ServletUnit) but SimpleTest Web tester can only work against URLs.
Ground rules
These are some rules I made for myself over the years. They aren’t definitive and to be honest I break most of them from time to time. But if you adhere to those rules your functional tests will be a lot more manageable.
In addition to these the general rules of unit testing also apply of course.
Isolate the application under test
Generally it’s very useful for the tests to run in the same process as the web application under test. This way in-memory databases can be used which makes test suites a lot more stable. At the same time this means that only your tests can access the application and change the state.
If you can’t use an in-memory application, at least try to start up the server at the beginning of the test suite. The worst thing you can do from a stability perspective is to test against some shared deployment of your site.
For example I’ve been responsible for testing a classifieds listing site in the past. The tests created a classified listing using the web form, then checked if it was in the search result, etc. All of this was running against a central test server which also was used by the developers to try out the current version of the code. While this mostly worked, from time to time the tests would fail because some user or another test run was changing the listings. This caused test failures that were very hard to reproduce and were bugs in the tests – not in the code.
Don’t mock
In functional tests you should mock as little as possible. You should really treat the system under test as a blackbox and not know about all the method calls it will execute. In this context, mocks will make your tests very fragile.
To isolate the system you may use test databases (using sqlite’s :memory: for example) or dummy services instead of mocks.
Use Page Objects
You probably want to test the HTML output. For that you’ll need some selectors such as XPath expressions or CSS selectors to access the page contents. You’ll rely on parts of the DOM structure such as element names, CSS classes or IDs for that. Instead of hard-coding those in every test, create page objects. So then when the page layout changes, you’ll only have to adjust the page objects, not every test.
A very simple way to create a page object is to have one class per page type and define property on that. For example:
from lxml import etree
class Page(object):
“”“Page object base class. Instantiated with some <span class="caps">HTML</span>.”“”
def __init__(self, body):
self._body = body
self._doc = etree.fromstring(body)
def __str__(self):
return self._body
def _get_text(self, xpath):
return self._doc.xpath(‘string(’ + xpath + ‘)’).strip()
class DetailPage(Page):
def get_title(self):
return self._get_text(‘/html/head/title’)
def get_page_title(self):
return self._get_text(‘//h1’)
This is just a simple example of how to do this. It expects a valid XML document as input as it uses the lxml parser. You could instead use BeautifulSoup or something similar.
An example for using these page objects:
def test_get_item(self):
"""app is an instance of webtest.TestApp"""
response = app.get('/item/id')
page = DetailPage(response.body)
assert page.get_title() == 'Test page - Memonic'
assert page.get_page_title() == 'Test page'
This assumes an existing app object where the test executes a request on. It then checks that the head title and page title are of the expected value.
Conclusion
Functional tests can mean a lot of satisfaction as they test the actual application. Some of my best success moments are when doing test-driven development with functional tests without ever opening a browser. It really allows me to get in a state where I just focus on what I want to accomplish and stay in a very productive mode.
If you have followed my tutorial so far, you now have a solid testing framework, good unit tests and can now progress with testing the meat of your application with functional tests.
In the next installment I’ll cover testing of the Javascript in your application.
Setting up a full stack for web testing
Many developers see the value in getting started with testing their web
applications, but don’t know how to actually start using it. I’ll write about a variety of products and processes which cover the whole range of testing web applications. The posts in this series will be published in the coming weeks. You can find a rough table of contents below but the list may get modified or extended.
Approach
Initially you must spend some thoughts on how you want to approach testing. The main obstacle is that almost always you start with an existing project that already has a big code base. It seems impossible to ever get enough testing in place to be meaningful. But my experience shows that even very little coverage can already improve quality of your system a lot.
I recommend to enforce two very simple rules:
- No bugfix without a test.
- Develop new features using the test-driven methodology.
But whatever happens, don’t go and try to implement 100% code coverage for your legacy code. That will kill you – and drive motivation down very quickly.
Implementing a test for each bugfix is very little work. To fix the bug, you have to reproduce the problem anyway. During that process you will find at least one test case that can be implemented in an automated fashion relatively easy.
The first few tests will be the hardest. But don’t be discouraged by that, it will get easier. It’s hard mainly for two reasons. First and most important, testing is something you have to learn. You didn’t learn your programming language in just a few minutes either. Second a lot of software is not written with testability in mind.
I hope this series will help you getting better with both these aspects.
Table of Contents
This table of contents will get updated when I write the articles. Keep coming back to it.
- Introduction
- Testing framework
- Unit testing
- Functional testing
- JavaScript testing
- Continuous integration
- Test-driven development
- Testability
- Measuring coverage
Autofill birthday fields in Safari
The Safari web browser can autofill form fields from your personal address book card. I’ve had very good experiences with this feature. But today I was creeped out a little on my brightkite profile as I saw my birthday even though I had not provided it anywhere. It took me a moment to realize that Safari had autofilled my birthday.
So I quickly came up with an evil idea. Would it be possible to abuse that feature to automatically collect birthdays from users on say a signup form?
And yes, it’s possible. Save the following HTML on your disk:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>
Settings - Profile - brightkite.com
</title>
</head>
<body>
<form action="http://localhost/" method="get">
<label for="fullname">Full name</label>
<input id="fullname" name="fullname" />
<input type="submit" />
<input id="street" name="street" />
<input id="dob" name="dob" style="opacity:0" />
</form>
</body>
</html>
It defines a form with the three fields full name, street and birthday. The birthday field is hidden – so the user has no idea that it will be submitted as well. The street field is just in there for easy checking if the autocompletion is working.
Then open the form in Safari (I tried on Version 4 Public Beta 5528.16), enter your full name in the first field and use the tab key to activate the submit button. If everything worked, you’ll see the street field autofilled as you’d expect. But when you submit, the birthday is submitted as well – if you have it stored in your address book.
Firebug 1.0 Beta
The new version of Firebug is now available. It’s the 1.0 beta release. It contains some great new features and I’d advise you to try it out if you develop web sites.
Joe was pondering to make the new version a commercial release. Instead he has now decided to leave it Open Source but asks for donations.
HTTP debugging
As a web developer I often have to debug HTTP problems. At local.ch we also do the frontend/backend communication using the HTTP protocol, so sometimes I also have to debug that. So over the whole time I’ve been doing that, some tips have accumulated.
LiveHTTPHeaders
LiveHTTPHeaders is a Firefox extension that allows to see the headers exchanged between the browser and server. It adds a “Headers” tab in the page information. This window can be accessed with Apple+I on the Mac or Ctrl+I on Linux and Windows. The headers tab shows a list of the headers that Firefox sent to the server and a separate list of the response headers sent by the server.
I use that mostly to see the Cookie and Accept-Language headers that Firefox sent.
Firebug
The Firefox extension Firebug is a debugging tool. It has JavaScript debugging, a DOM inspector, debug messages and a lot more. But the most useful feature for this article is XMLHttpRequest logging. After opening the console you can enable the option “Show XMLHttpRequests” in Firebug’s Options menu. This logs the URL including complete request and response of every XMLHttpRequest done.
GET requests with netcat
Netcat is in my experience one of the most overlooked tools for network debugging. It allows you to easily send network requests to any TCP or UDP server. While you can also open TCP connections with good old telnet, netcat offers one big advantage: it reads the data to be sent through the standard input channel. This allows you to replay requests a lot easier than with telnet. For example I usually do the following in a bash shell:
echo “GET / HTTP/1.1
Host: weblog.patrice.ch
Connection: Close
“ | nc weblog.patrice.ch 80 | less
This opens / and shows the full HTTP responses in less. Let me explain the three requests lines for those who never have seen raw HTTP:
GET / HTTP/1.1: Get the page at the absolute path / using HTTP 1.1.Host: weblog.patrice.ch: This tells the web server that we’d like to retrieve the absolute path given in the previous line from the weblog.patrice.ch host. This must be specified with HTTP 1.1 and allows the server to serve different sites from the same IP address.Connection: Close: This turns off Keep-Alive. The server can free resources more quickly and the TCP connection is closed immediately.- Empty line: This three lines are followed by an empty line. In HTTP the first empty line separates the headers from the body.
The HTTP request is piped to the nc command, netcat. The two parameters signify that we want to open a connection to weblog.patrice.ch on port 80. Instead of weblog.patrice.ch you could also provide it’s IP address.
POST requests with netcat
Even more useful is doing POST requests with netcat. An example would be:
echo “POST /test.php HTTP/1.1
Host: myserver
Connection: Close
Content-Length: 10
key=value” | nc myserver 80 | less
This sends the data key=value to the server. You have to specify the Content-Length header so the server knows how much to read. When the request data is all in one line you can easily count the number of characters in your editor. Just place the whole line in your editor, position your cursor at the end of the line and look at the column that your editor gives you. That number minus one has to be used as the content length.
With longer requests I usually edit the request in a file saved on the disk. I then invoke netcat with the following command:
nc myserver 80 <request.txt | lessThat’s a bit more comfortable for large data than editing everything in the shell.
Netcat is included with Mac OS X. Thank you Apple.
tcpdump
When investigating the backend/frontend communication I sometimes have a need to see exactly what’s going over the wire. Tcpdump shows you the communication in that case.
sudo tcpdump -efli en1 -XX -s0 | tee /tmp/tcpdump.logThe params I use are the following:
- -e: Print the link-level header on each dump line.
- -f: Print `foreign’ IPv4 addresses numerically rather than symbolically (I like IP addresses more then hostnames in this context)
- -i en1: Listen on interface en1 (my wireless interface). Have to use en0 for my network card
- -XX: Print packets in hex and ASCII
- -s0: Print whole packets, not only first 68 chars.
The tee command shows me the data on the screen while everything is also logged into /tmp/tcpdump.log for later consultation.
If you’re only interested in one specify communication, you can add some filters. For example:
sudo tcpdump -efli en1 -XX -s0 'port 8080' | tee /tmp/tcpdump.logThis command will only include output going to or coming form port 8080. The tcpdump man page gives extended information about the possible filters.
Tcpdump is included with Mac OS X. Thank you Apple.
dig
Often I need to do some DNS debugging. This is not directly related to HTTP but very often the problem is actually in the DNS system when something doesn’t work. A lot of people use nslookup for doing name server lookups. I prefer dig. Let me show you a few commands:
- Look up a host:
dig www.local.ch - Very short output:
dig +short www.local.ch - Reverse-lookup of an IP address:
dig -x 195.141.88.144(no need to manually put together the in-addr.arpa address. - Again with very short output:
dig +short -x 195.141.88.144 - Check at a specific name server:
dig @ns1.local.ch mail.local.ch - Get MX record:
dig local.ch MX(If you leave out the type dig searches for A records)
I think dig is part of the BIND distribution. It’s included with Mac OS X by default. Thank you Apple. (Yes I know I repeat myself)
Conclusion
I presented the following five tools:
Those tools are basically everything I use for debugging of HTTP requests.
Please leave any questions or contributions in the comments.
Testing with Selenium
I spent Friday and Saturday at the T.Camp of the Swiss Web consultancy namics. That’s a yearly conference for the namics techies. As a member of the namics sister company local.ch I was also allowed to participate. And like every year for the past five years I held a presentation again. This time I talked about testing. Specifically Selenium.
It’s much the same as I’ll talk about on September 12 at the Webtuesday event.
You can download the presentation.
August Webtuesday: UTF-8
We'll meet at 19:30 at the local.ch offices (sixth floor - call me at 079 755 53 67 if the doors are locked and you don't see anybody). Afterwards we'll head to Cheyenne for food and drinks.
PS: Sorry for not posting for a while. Will try to get some more posts out again.
Safari Javascript debugger
Ajaxian reports that Safari gets a Javascript debugger.
"Webkit - the development version of Safari, has gotten a real javascript debugger. Its called Drosera, and the Surfin Safari blog has the announcement. Or you can just download the latest nightly of Webkit and go."
I downloaded it and gave it a try. But I must confess I got stuck very early. I didn't even find out how to debug an external script file. Did anybody have any success with Drosera?
Book Review: Building Scalable Web Sites
Management review: the book is worth a read.
Technical short review: the book covers a lot of stuff a bit and nothing extremely well.
The book does not completely live up to it's title as scaling is only part of the book. It seems more to be a list of lessons learned while building Flickr.
That's also the reason for one of the book's main deficiencies: it's mostly PHP and MySQL only. But it also includes enough lessons that can be applied in other environments for it to be useful.
A short chapter by chapter review follows.
- Introduction: Doesn't need a review.
- Web Application Architecture: Interesting notes about building the architecture of your application. Including parts about hardware and networking.
- Development Environments: A few quick tips about using source control, deployment, testing, etc. Stuff that's covered a lot better and in more depth in many other places.
- i18n, L10n, and Unicode: Notes about internationalizing an application, translating, etc. If you have worked with Unicode before there is not much new information here.
- Data Integrity and Security: Filter all your input and output. Good for Cal that he includes this, because too many Web developers still fail at this. And many other books don't include it so all new new legions of Web developers come out without this knowledge.
- Email: Flickr does Email handling for moblogging. As I wrote that part for the KAYWA weblogs I know how frustrating this can be. That's why section 6.7 is titled "Mobile Carriers Hate You". All in all the chapter mainly covers dealing with incoming email including how to handle attachments.
- Remote Services: Interesting information about how to handle remote services and also communication in your application. I found section 7.5 particularly interesting where Cal describes an asynchronous service and how they implemented it for the photo uploads on Flickr.
- Bottlenecks: Preparing you for the scaling chapter. How you identify where your application is slow.
- Scaling Web Applications: The chapter that set the book's title. A lot of information but in my opinion it doesn't go deep enough.
- Statistics, Monitoring, and Alerting: Basically only explains a few tools for gathering statistics of the system. The section on alerting could just as well have been left out.
- APIs: How to publish your content with a few APIs. RSS, Atom and Web Services are the buzz words that describe this chapter.
All in all I have mixed feelings about this book. It's nothing earth-shattering but certainly worth a read. If you can read it online on Safari it's well worth to be added to your library for a while. If you have to shell out the money for that book, you will have to decide for yourself whether you can learn enough from it for it to be worth the money. It wouldn't have been worth it for me.
No real Internet
--- www.heise.de ping statistics ---
89 packets transmitted, 61 packets received, 31% packet loss
round-trip min/avg/max/stddev = 16.566/20.503/45.173/5.434 ms
It's unusable.
Webtuesday Zurich
We then moved to El Lokal for a beer and Pizza. We of local.ch had to accept being defeated by tel.search.ch for looking up the number of a Pizza delivery service. But only because we don't have the mobile interface ready, yet. It's already being implemented, though and is one of the lacking features I personally care most about.
It was once again interesting to meet a few people I had only met online so far, especially Denis De Mesmaeker and Alain Petignat.
Next time I'll talk about Ruby on Rails which I already defended at our table yesterday. We planned/are planning to have that event on June 13 but that date collides with the Swiss victory over France at the Football World Cup. Details are currently being negotiated and will be announced on the Webtuesday Zurich Web site.
webtuesday
See you there!
Results
I guess I'm finishing my reporting now as my battery won't stand much more time with me today. I liked the event because I was able to talk to some people I have long known online before (Chregu for example). Now I also know them personally. And I was able to meet some old contacts.
It's started
bloggrrr was introduced and is disappointing. Or Leu has to explain it better to me. It's really not more than evaluating which weblog is the most popular one.
Mass media and media for the masses
Martin Haslebacher considers blogs as an important part in today's life. He talked about how they can also serve as sources but they will want a second source to confirm the weblog. I assume that's the standard approach with any source in journalism. Also they want to use (existing) blogs in their area to enrich the escpace platform as an additional value for their readers.
Bruno Giussani asked if the person was a blogger who filmed the waves of the Tsunami in Asia arriving at the coast and sent that movie to the media. Julika Hartmann countered that she might define him as a blogger if he'd do that regularly.
Nick Lüthi, the moderator of the discussion, asked Martin Haslebacher what their business model was about adding blogging to their services. They currently don't have a business model but their existing business model is under pressure by new media. An example he used was craigslist.
Martin Haslebacher said, that they'd have to develop some model to pay bloggers for their contributions. They don't seem to have anything finished yet, but they are aware of the issue.
I tried very hard to understand the French contributions by Bruno Giussani and Jean-Christophe Liechti. To same extent I succeeded but it was hard and I definitely have to learn French again. I lost it by learning Spanish in Peru.
Lots of photographers. And the room is really too dark.
KAYWA en español
 El proveedor de weblogs de Suiza KAYWA ya esta disponible en español también. Eso significa que ya puede usar el interface de administración en los cuatros idiomas inglés, alemán, francés y español. Yo hice la traducción en español y por eso creo que no esta perfecto todavía. Si tu idioma maternal es el español y quieres ayudar en mejorar la traducción podemos darte una cuenta gratis de KAYWA. Si quieres una cuente de KAYWA puedes escribir me en los comentarios o por correo electrónico.
El proveedor de weblogs de Suiza KAYWA ya esta disponible en español también. Eso significa que ya puede usar el interface de administración en los cuatros idiomas inglés, alemán, francés y español. Yo hice la traducción en español y por eso creo que no esta perfecto todavía. Si tu idioma maternal es el español y quieres ayudar en mejorar la traducción podemos darte una cuenta gratis de KAYWA. Si quieres una cuente de KAYWA puedes escribir me en los comentarios o por correo electrónico.Yo ya voy a escribir más en español en este weblog. Si solo quieres leer los artículos en español puedes visitar http://weblog.patrice.ch/es o subscribir al canal http://weblog.patrice.ch/es/atom/. El canal principal en http://weblog.patrice.ch/atom/ mayormente contiene artículos en inglés pero también a veces en alemán y español.
freeflux.net and the Swiss feed directory
In Chregu's feed all blogs with 10 posts or more and at least one post in the past 30 days are included.
My original call to arms still holds and I will cite it here:
If you are a blog provider in Switzerland or have an easy way to extract only Swiss weblogs, feel free to publish your active weblogs as an OPML feed. It's probably best to follow the format I use for the feed directory OPML. Once you have done that, send me a mail with the feed's URL.
Blog list now allows entries without feed URL
But one problem surfaced. There are weblogs that don't have an XML feed (RSS or Atom). But the feed URL was obligatory in the list and I even actively deleted submissions without feed URLs. After all, the list is mainly for the aggregators. Or is it?
I currently know of the following services consuming the provided OPML feed:
- Planet Switzerland
- ping.blogug.ch
- Swiss Top 100 Blogs
- Swiss weblog statistics
- Swiss Blogs Gallery
- blog.ch (though I'm not sure if Matthias just imported the list once)
- Nominations for the 1st Swiss Blog Awards
I just now realize that there are already quite some applications using that OPML feed. Cool! But anyway, of the seven sites listed, only about two really care about the feed URL (planet and blog.ch). I assume for the others the page URL is sufficient.
In short, after the inquiry by Jan I quickly rethought my previous stance on the topic. Feed URLs are no longer obligatory for listing your blog in the blog directory. Though personally I still believe a blog isn't a blog without a feed, the minority of blog tools who thinks otherwise is sufficiently large for me to feel tolerant and include them.
The OPML feed by default only exports blogs with a feed URL to maintain backward compatibility. To include all blogs without feed URLs as well, just append "?nofeed=1" to the URL. For example http://list.blogug.ch/opml?nofeed=1. There is an extended OPML help on the blog directory site.
How this explanations weren't too geeky and complicated.
What are your comments about this change?
Nominations for the Swiss Weblog Awards
- The Best of Swiss Blogs
- «Zum Runden Leder» - Funniest blog in Switzerland.
- Pendlerblog - Interesting, funny.
- Beobachtungen zur Medienkonvergenz - Good coverage of Gadget news. Though the gadget stuff now goes to neuerdings.com which I don't nominate because it's too young.
- namics Weblog - Jürg does a great job of putting good technical content on that blog.
- Rookie-Award
- Switzerland World Cup Blog - Good coverage of Swiss world cup preparation. Promises to become the most-read Swiss weblog in a few months.
- Beobachtungen zur Medienkonvergenz (again)
- cake baker - Innovative content about a new Rails-like PHP framework (how many are there of those anyway, something like 200?)
- Best Multimedia-Blog
- Photos from Ernscht Though I don't know if this already qualifies as multimedia blog. I like it because of the one-photo-a-day-at-9'oclock-diary
I have to admit, that most of these nominations are friends of mine (Konvergenz, namics, Cakebaker and Ernscht).
Should I change my nominations, I'll update this article here.
monblog.ch and the Swiss feed directory
I suggested he provide an OPML feed that I can import and so he did. So starting today, monblog.ch weblogs are automatically added if they have at least ten articles, are older than three days and have published an article within the last month. I don't check those conditions myself, but Antonio only corresponding publishes weblogs in the OPML feed.
If you are a blog provider in Switzerland or have an easy way to extract only Swiss weblogs, feel free to publish your active weblogs as an OPML feed. It's probably best to follow the format I use for the feed directory OPML. Once you have done that, send me a mail with the feed's URL.
Wer hat die Daten gelöscht?
blogug Updates
Stefan provided a nice favicon for the blogug project. I integrated those into "my" two sites (list and stats). Thank you Stefan!
On the stats page I did a few detail fixes in the translation. And more important, the blog provider twoday.net is now recognized correctly. They even made it into the Top 5, which currently is:
- WordPress: 309
- Blogger: 166
- Kaywa: 136
- Flux CMS: 31
- twoday.net: 30
I am saving those software statistics historically, so in a few weeks I'll start providing the "historical development" stats to see how the market shares of the different tools and hosters develop over time.
Deep deep links from Yahoo! to Wikipedia
That's what Yahoo! search now does for Wikipedia.
Search for Switzerland and you'll get this:

This result directly links to the subsections "History", "Politics" and "Direct democracy" of the Switzerland article. Now don't ask me what's the algorithm for selecting the subsections, but it's a pretty cool feature.
This is similar to the Google feature where Google will sometimes provide deep links into the site. I never use Google, so the only example I know is when you search for Stanford:

Those links Admission, etc. link to other pages on the Stanford Web sites. That's an intelligent idea as well. Though again, I have no idea what algorithm this links are based on.
(Via Yahoo! search blog and they get bonus points for using coffee as the example.)
Using Jabber to query Swiss phone numbers
I have now added this to my Adium client and it works fine. What's missing is looking up the name for a phone number. And the output doesn't format the phone number very nicely.
(Via 2ni, search.ch CTO)
namics Intranet Fachtagung
Klickt also folgenden Banner an, falls ihr denkt ihr habt an einer Intranet Fachtagung Interesse. Ein Intranet der namics wurde in die jährliche Intranet Top 10 der Nielsen Norman gewählt, also sollte namics doch etwas zum Thema zu sagen haben.

Disclaimer: Ich habe einige Jahre für namics gearbeitet.
Swissinfo offline
I noticed a few minutes ago that NetNewsWire reported some error for the swissinfo.org domain. Tried to surf the site with Firefox and indeed, I got a "Server not found" (or rather "Servidor no encontrado") message. So I used dig to verify that no DNS record is returned.
Some more debugging showed, that the domain is still active and points to the two DNS servers NS1.IP-PLUS.NET and NS2.IP-PLUS.NET. But those domain servers don't return anything for swissinfo.org queries. It seems, that IP-Plus has somehow misconfigured their DNS servers. Or maybe Swissinfo didn't pay...
I will notify the technical contact for the domain by e-mail, just in case he doesn't know about the problem, yet (very unlikely though).
Update: Definitely some IP-Plus problem. Checked swissinfo.ch, which lists the two name servers leo.srg-ssr.ch and ns1.ip-plus.net. The srg-ssr.ch one returns the names correctly (194.6.181.128 for swissinfo.org and a CNAME to www.swissinfo.org.edgesuite.net. for www.swissinfo.org). The IP-Plus one doesn't return any data for any of those domains.
Update: As Matthias noted in the comments, Swissinfo was online again a few hours after my post.
State of the Swiss Blogosphere 2005
Introduction
In this post I'm presenting you the state of the Swiss Blogosphere in the year 2005. In order to come up with this numbers and statistics I analyzed the blog.ch database. This report is part of a project I'm going to present in a few days. This report is of course inspired by David Sifry's "State of the Blogosphere" reports.
Weblogs
We don't have very precise numbers for the development of weblogs in Switzerland. Matthias only recently started to save the date of registration of the weblogs on blog.ch. So where it led to better results I used the date of the first known post on blog.ch to come up with a weblog creation date. This approach leads to quite reliable data for the year 2005.
Also the number of weblogs is probably quite a bit lower than the real number. The Swiss weblogs list knows about 1035 weblogs as of today. But German weblogs are over-represented which probably means, that many French and Italian weblogs are not currently listed. Compare these numbers:
- German weblogs: 736
- French weblogs: 137
- Italian weblogs: 12
The weblog list is a community project. So if you want to help out and add more weblogs, you are welcome to it.
But let's get down to business now. The monthly numbers of weblogs are listed in the following table:
| Month | Weblogs | Active weblogs | Active % |
|---|---|---|---|
| 1/2005 | 208 | 168 | 80 % |
| 2/2005 | 246 | 194 | 78 % |
| 3/2005 | 296 | 230 | 77 % |
| 4/2005 | 339 | 254 | 74 % |
| 5/2005 | 394 | 295 | 74 % |
| 6/2005 | 455 | 348 | 76 % |
| 7/2005 | 494 | 368 | 74 % |
| 8/2005 | 540 | 390 | 72 % |
| 9/2005 | 596 | 419 | 70 % |
| 10/2005 | 658 | 456 | 69 % |
| 11/2005 | 728 | 520 | 71 % |
| 12/2005 | 817 | 594 | 72 % |
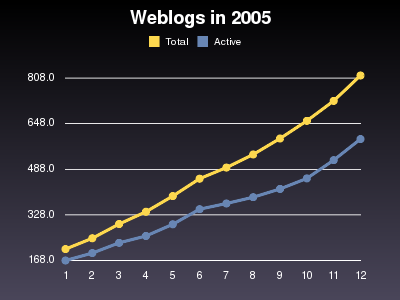
A weblog is counted as active, if a post was created in the past 30 days. This number of active weblogs is listed in the third column, while the fourth column shows how many percent of the known weblogs were active.
There were 186 known weblogs on January 1, 2005. This doubled to about 340 until mid-april and doubled again until October 22 when we knew about 673 weblogs. On December 31 we had 864 weblogs, 4.5 times as many as on January 1. So it's nothing like an exponential growth but it's solid enough. And a few days ago we hit 1000 weblogs in Switzerland.
The percentage of active weblogs has decreased quite a bit (from 80% to 72%). I imagine this number to drop down to 65 percent of maybe even lower. This is a natural development as people loose interest in their weblog and stop updating it. Also a few weblogs are opened for a single event such as a congress or a trip and are not updated after that.
Posts
Let's now have a look at the weblog posts in Switzerland. How many articles do the Swiss bloggers produce?
| Month | Daily average | Monthly total |
|---|---|---|
| 1/2005 | 118 | 3669 |
| 2/2005 | 131 | 3687 |
| 3/2005 | 145 | 4521 |
| 4/2005 | 168 | 5058 |
| 5/2005 | 196 | 6086 |
| 6/2005 | 241 | 7257 |
| 7/2005 | 227 | 7040 |
| 8/2005 | 247 | 7681 |
| 9/2005 | 279 | 8374 |
| 10/2005 | 271 | 8403 |
| 11/2005 | 305 | 9176 |
| 12/2005 | 315 | 9777 |
I created two different graphs for these numbers. One with 365 data points and the other with just 12. The first graph shows how posts vary a lot between the days of week. The second diagram is more suitable to read the growth. Both graphics show the number of posts per day.
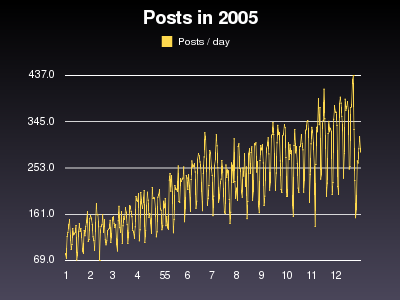
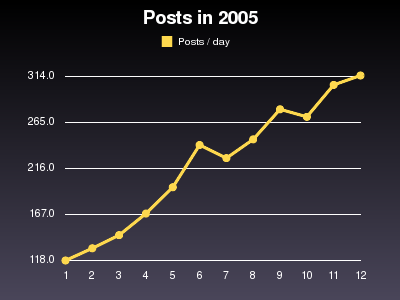
This graphs show a simple message: the number of posts has clearly increased. But the growth is noticeably lower than the growth of the weblogs above. In January 208 weblogs contributed 118 posts per day, 0.6 posts per weblog on average. In December there were 315 posts per day from 817 weblogs, 0.4 on average. Even when we only count in the active weblogs, this ratio is similar (0.7 daily posts per weblog in January and 0.5 in December). I think this shows that weblogs are not updated as often as before. If you have other interpretations for this numbers, please comment.
The graph of the daily posts clearly shows how the numbers vary between the days of the week. But how exactly does the distribution between the days of the week look? See the graph below:
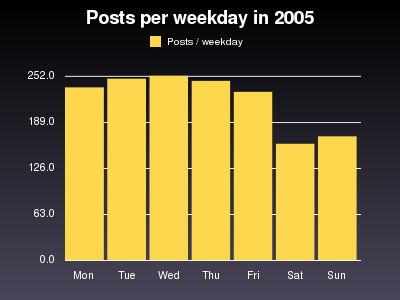
Saturday is the day with the lowest number of posts, while most posts are created on Wednesday. But the differences on Monday to Friday are marginal. Apparently many people blog from work.
Closing words
As a new blogug.ch tool I am currently working on a project to collect numbers from the Swiss Blogosphere every day. This will allow us to easily have access to reliable numbers about weblogs in Switzerland. I will introduce that project in a few days, so stay tuned.
namics banner
Too bad though, that clicking the banner leads to this page.
Will Google Maps ever be usable?
Do I miss something? Or is Google Maps indeed useless?
DRS Weblog
SuprGlu: My life in one place
- my weblog
- my pictures (via Flickr)
- my comments (via coComment)
- my bookmarks (via del.icio.us
- my books and movies (via Media Manager
- Media Manager weblog
- Recent changes of the Biblewiki (where I'm the only editor)
SuprGlu looks like a nice service. Please announce your SuprGlu pages here in the comments if you also have one.
(Via Ernscht and Steph)
1000 Weblogs

Most of the weblogs are imported from the blog.ch OPML file. Many have been added on list.blogug.ch afterwards.
All the current numbers of the blogug list:
- Confirmed weblogs: 1000
- Unconfirmed weblogs: 0
- Offline weblogs: 46
- Spam, non-swiss, duplicates: 10
- Registered users: 171
- Claimed weblogs: 98 (list currently not easily visible on the Web put I'll probably implement this)
If every one of these weblogs were written by a different person, then about 0.015 percent of all Swiss people would have a weblog (using the current Wikipedia number of 7'415'100 inhabitants).
Just discoered: IR weblog
Monitor your comments around the Web
Or that's the idea. The problem is, that currently only comments of other people who use coComment are included. So if somebody who does not use coComment does reply (the vast majority of commentors) you will not see the reply in your coComment views.
Anyway, I'll try it out for a while and see where it's going. And I'm still wayiting (impatiently) for Chregu to implement the comment support into the planet (now that list.blogug.ch includes comment feeds).
Updated to add: found this via the blog.ch weblog and Jérôme. Jérôme also provided me with the invitation code and probably still has some left.
search.ch Immo search out of beta
Anyway, the search.ch team has done a very nice job. They fixed my issue with the beta version and it now also works on lower screen resolutions (while i do have 1024x768 most of my windows don't run maximized).
And there is one big thing that sprang to my attention and really got me grinning and jumping and wowing and all the rest. They remember your last search when you left the application and zoom back into your search. For example last time I looked for apartments in Wigoltingen. Now I returned to the application and it zoomed the map back to Wigoltingen.
While this is technically not a big thing (at least from my point of view) it gives a huge productivity boost to the user. The general immo use case is a person who looks for an apartment in the same place over a certain period of time, checking out different apartments or houses. If that place happens to be Zurich, this may go on for several months. So whenever that person returns to the platform, he will generally want to run the same search again.
And they provide RSS feeds of new ads in the given map region.
I hope I have to look for an apartment soon, I want to use that Web site...
Great job dear search.ch. Should you people responsible for this incredibly cool product ever show up near my location, give me a call and I'll invite you to a beer.
Doodle: Schedule events
(Via Medienpraxis)
Comment feeds on list.blogug.ch
And then there is a question to you. I'd like to add news feed to that directory as well. Originally it was intended by me to be a feed directory, not necessarily a blog directory. So I'd like to add for example the SF Tagesschau feeds to the list. But I guess I would then have to introduce a category so that consumers of the list still can only get weblogs.
What are your thoughts about this idea?
Yahoo! stays on track
Now the people over at the Yahoo! Search blog contradict that news story and say:
There's been a lot of conjecture and confusion today about Yahoo!'s commitment to being the world's best search engine-talk which anyone who's been following the evolution of Yahoo! Search would have realized is… just plain wrong.
I'm personally glad to hear this.
New blogug.ch Design
- blogug.ch homepage (by Alain)
- Ping (by Chregu)
- Swiss Top 100 Blogs (by Chregu)
- feed directory (by Patrice, ahm that's me)
So thank you sis for that wonderful new design.
Oh and the OPML export now includes an ID.
blogug.ch results
Meanwhile Alain (who also provides the blogug.ch domain name) announced the gallery of Swiss weblogs.
Leu then compiled a 30 seconds blog movie from the screenshots.
I'll try to include the screenshots into the blog list next week. Also I'll have to find a way to automatically add new blog.ch subscriptions to the blog list because most additions still are added over there. Also I'll have to work with Matthias on the URL sheme. Because I manually normalized all URLs in the blog list (adding slashed to domain names for example) he missed many of the tags (see his blog tags where many blogs lack the language tags which I have added to every blog).
So stay tuned for the update, I'll try to do something next week.
NZZ mit RSS
Scheint aber so, dass die NZZ endlich im 21. Jahrhundert angekommen ist (sorry, bin ein bisschen gemein). Willkommen.
Expat blog directory
Julien, who maintains the project, started the project because he himself spent a few yours outside of his country France.
Update: Forgot to say, I found this via iFeedYou.
Konferenzen Anfang 2006
Erstens die LIFT06 in Genf am 2. und 3. Februar.
LIFT has a simple goal: connect people who are passionate about new applications of technology and propel their conversations into the broader world to improve life and work.
Die Liste der Speaker ist sehenswert - vor allem für eine Schweizer Konferenz.
Zweitens findet am 8. Februar in London ein Workshop mit dem Thema The Future of Web Apps statt. Da ist die Liste von Speakern noch eindrücklicher (Yahoo! mit Joshua Schachter von del.icio.us, Eric Costello von Flickr und Tom Coates, Google mit Steven Crossan, David Heinemeier Hansson, und andere). Der Workshop kostet läppische 75 Pfund. Nichts wie hin!
New, open and independent feed directory
Okay, Christian Stocker's comments inspired me to write a new feed directory. The fact that I implemented Christian's ideas so quickly shows, that I agree with his points completly. A short summary of what sub.scribe.to is supposed to be and have in the future:
- A list of Swiss weblogs
- Maintained as a community effort
- A list of "confirmed" weblogs (confirmation by trusted community members)
- Weblog categorization, so that Weblogs for just one language or a topic can be exported (basic tag support exists)
- OPML export
Also I like some of Christian's other ideas such as pinging or blog claims. See also the about sub.scribe.to site.
Language selection
A short summary of Jürg's post:
- The user decides actively what language he wants (if necessary by showing a language selection page before going to the content)
- The user only has to decide once
- The switch is in the top right corner. Always.
- Don't use flags but text for language switch links
- The laben consists of at least two characters and is written in the target language (so you always write Deutsch, Français, English, Español, ???, etc.)
- The language is contained in the URL - don't use query string parameters
So far I didn't like the solution which Apache content negotiation dictates. But how it's implemented on search.ch and described in Bernhard's posting, I actually think it makes sense. First let me quote my comment on Jürg's weblog:
Gebe dir in fast allem recht. Nur vorgeschaltete Sprachauswahlseite finde ich uncool und ersetze ich mit Auswertung von Accept-Language. Wenn man damit 80 Prozent der Benutzer an den richtigen Ort geleitet hat spart man denen bereits allen einen Klick. Und die anderen 20 Prozent haben auch nicht mehr Klicks als mit Auswahlseite.
Ich vermute aber sowieso, dass man mit der Methode weit über 90 Prozent bereits ans richtige Ort leitet, da sehr viele Benutzer den Browser in ihrer Standardsprache verwenden und eben an den Default-Einstellungen nichts ändern.
Die Content Negotiation Methode von Apache finde ich eigentlich ganz gut. In der Praxis hat sie aber den Nachteil, dass aktive Sprachauswahl genau nicht berücksichtigt wird. Debian.org verwendet diese Methode. Wenn ich da auf einer Seite von Spanisch (meine Standard-Sprache) auf Englisch umstelle, erscheint die nächste Seite doch wieder auf Spanisch. Das liegt daran, dass Links nie auf eine explizite Sprachversion sondern immer auf die unqualifizierte Version des Dateinamens zeigen. (also auf index.html und nicht auf index.en.html).
So to summarize and translate this: I think Jürg's points are valid, that automatic language selection based on HTTP Accept-Language is a good idea (if it can be manually overriden by the user) and that Apache's content negotiation doesn't work in practice while it sounds very nice.
As an example of content negotiation gone wrong I used the Debian Web site. My browser is set to Spanish, German and English (in that order). It's this way, because I really want to browse most pages in Spanish when possible (in order to learn that language) but sometimes have to switch, because I don't understand it. And it turns out that on the Debian Web site I have to switch occasionally. Now after I switch from the Spanish language to the English (or German one), all links are language neutral again. So when I click a link I get back to the Spanish version and again have to switch to my current language of choice.
The search.ch solution solves this and remembers the user's decision. Links are also automatically constructed to point to the right target. But let me quote Bernie on that:
But the interesting details are within the initial detection and the URIs. An URI could end in help.html, but also in help.en.html; exactly how Apache content negotiation suggests, i.e. the first one would trigger automatic language detection, the second one is fixed on english. The important difference is in how the links in these pages look. We took great care (and credit for this goes to Urban Müller) to keep the links on those documents in the same style. That is, the help.html document would come in the user's language (e.g. german) but wouldn't contain language links (e.g. .de.html). Thus, the url would also reflect the information the user put into the system: The language was only set if it was actually overrided by the user.
My conclusion is, that automatic language detection is okay (and should be done) but when the browser and the user disagree, the user's decision should be worth a lot more. Though I think I may review this opinion based on Peter Hogenkamp's comments. He knows quite a bit about usability. In the comment he writes about how the Web site of Swiss International Airlines always defaults to English and many users don't switch to their language (this was actually tested with users):
Der doofe User kann ja jedes Mal die Sprache wechseln. (De facto macht er das nicht, sondern er kämpft sich durch, selbst wenn er gar nicht so gut Englisch kann, wie wir in einer Testserie für die Netzwoche gesehen haben, mit den zu erwartenden negativen Folgen.
But Swiss violates my main point: use Accept-Language for initial language detection. So I'm currently not prepared to accept the example of Swiss as an example against my basic rules. I'm stating them again here for quick reference (and will notify you should I change that opinion).
Automatic language detection is okay (and should be done) but when the browser and the user disagree, the user's decision should be worth a lot more.
Places where Ajax should be used
Just the basic list here, head over to Alex to read the details:
Here are places Ajax should now be required in a web application:
- Form driven interaction
- Deep hierarchical tree navigation
- Rapid user-to-user communication
- Voting, Yes/No boxes, Ratings submissions
- Filtering and involved data manipulation
- Commonly entered text hints/autocompletion
Here are some places Ajax shouldn't be used:
- Simple forms
- Search
- Basic navigation
- Replacing a large amount of text
- Display manipulation
- Useless widgets
I currently can't think of any obious disagreements to his points.
Firefox 1.5
And now it's time to test out some CSS 3 features. Apparently Firefox 1.5 supports that partly.
A full changelog since 1.0.7 is available.
Update: I tried out CSS 3 columns in my blog. Works fine with Firefox but sucks in my current layout because the text is narrow enough already for good reading. But looks quite good for example in Robert O'Callahan's weblog. One problem is immediately evident, though. Reading a long article requires you to scroll up again when you reach a column end. Read for example Frame Display Lists and tell me if you dislike it as much as I do. But of course, if you browse his site in any other browser than Firefox 1.5 (and other Gecko 1.8 based browsers) you won't see any columns (or so I would assume).
Search Engine Experiment
Danke an Peter für den Hinweis.
Mobile del.icio.us
mobdel's URL layout it the same as with del.icio.us. The PHP script is available in the Public Domain (which means "do with it whatever you feel like today"). So feel free to modify it, hack it, enhance it, make it more complex, etc.
You can check my for_mobile tag to see my current favourite mobile Web sites.
Flickr tag clusters
Holy freaking Ajax
Das neue Yahoo! Webmail ist momentan Beta und meines Wissens noch nicht öffentlich.
Flickr Web statistics
For example here somebody arrived this week searching for pictures of Mollendo (keyword is contained in an article with lots of links to Flickr). And indeed when I search for Mollendo photos on Yahoo! my Flickr page comes up second and one of my pictures third. When people search Mollendo pictures on Google they get my Weblog very highly placed. There Flickr is quite a bit worse off - page three.
AJAX Unit Testing
Dann kam noch Ruby on Rails dessen einfaches und integriertes Testing ein zentraler Grund für meine Begeisterung war und ist. Rails bringt in den neueren Versionen integrierte Unterstützung für AJAX mit und ich vermisste immer wieder die Unit Tests für den ganzen Java Script Code. Doch es sieht so aus, als könnte ich in Zukunft auch Java Script mit Unit Tests ausrüsten:
Mochikit is a highly documented and well tested, suite of JavaScript libraries that will help you get shit done, fast. We took all the good ideas we could find from our Python, Objective-C, etc. experience and adapted it to the crazy world of JavaScript.
Ich hatte bisher keine Zeit, das Framework auszutesten, werde das aber definitiv nachholen und hier berichten.
(Via lesscode.org.)
Technorati auf dem Mobiltelefon
Seit einiger Zeit bin ich ein ziemlicher Fan vom mobilen Web. Angesteckt mit dieser Sucht hat mich der Roger. Irgendwann muss ich mir mal eine gute Liste mobiler Dienste zusammen stellen. Momentan sind das vor allem Wapedia, Google Mobile und KAYWA Mobile.
Und jetzt gibt es Technorati Mobile. Mal schauen, ob es eine Möglichkeit gibt, denen beizubringen da die mobile Version meines Weblogs zu verlinken. (Via Technorati Weblog)
Ich überlege mir gerade, ob es eine Möglichkeit gäbe, für die mobile Version eine RSS/Atom Extension einzuführen.
Mein Name im Toronto Star
Patrice Neff is a software developer based in Switzerland who uses del.icio.us to share links with a partner on a shared development project. And Cyprien Lomas, an academic technology expert at the faculty of agriculture at the University of British Columbia, uses del.icio.us tags to reconnect with colleagues in the tech field.
Ich mag mich noch erinnern, wie die Autorin auf der del.icio.us Mailingliste nach Einsatz-Beispielen gefragt hat. Dass ich aber im Artikel namentlich erwähnt würde, hatte ich nicht erwartet. Der Artikel, wie er veröffentlich wurde ist bei Alexandra Samuel online. Und zwar in der vollständigen Version sowie in der veröffentlichten und gekürzten Fassung.
Der Artikel bietet eine low-tech Einführung ins Tagging und erwähnt dazu die Seiten del.icio.us, Flickr und Technorati. Ist ein guter Text für jeden, der sich noch nicht mit Tagging auseinandergesetzt hat.
Atom 1.0
Okay, die Spezifikation ist ja auch noch nicht mal eine Woche alt... Da gibt es ja schlimmere Fälle. Und wenigstens hat Microsoft noch keinen Atom Feedreader veröffentlicht, sonst würde es drei Jahre gehen, bis die mit der neuen Version umgehen könnten. Naja, eher länger. Schliesslich kann der aktuelle Internet Explorer noch immer nicht korrekt mit CSS 2 umgehen. Und CSS 2 ist aus dem Jahre 1998. Sieben Jahre "and counting"...
Ich verliebe mich in Flickr
Anyway, wegen Flickr. Zum Eingewöhnen bin ich dran mit dem erwähnten Script mal alle meine Japan-Bilder hochzuladen. Und ich muss sagen, Flickr ist dank der neuen XMLHttpRequest-Funktionen schon benutzerfreundlicher als die meiste Desktop-Software in dem Bereich! So langsam kann ich mir echt vorstellen, komplett auf Flickr umzusteigen statt lokal nochmals eine Software zu haben. Einziger und grösster Nachteil: wenn ich bei Freunden bin und zum Beispiel noch kurz meine Japan-Fotos zeigen möchte, sehe ich alt aus, wenn kein guter Internet-Zugang vorhanden ist. Und wenn das Rotieren und Präsentieren der Bilder ohne Flash ginge, dann wäre ich überglücklich.
Die meisten meiner bisher hochgeladenen Bilder sind erst für Freunde und Familie sichtbar. Nach und nach werde ich die meisten öffentlich schalten. Wer jetzt schon einige der Bilder sehen möchte kann entweder auf meiner alte Japan-Seite vorbeischauen oder aber mich bei Flickr zu den Kontakten hinzufügen. Meine Bilder sind unter flickr.com/photos/patrice/ zu finden.
Google Web Accelerator gestoppt
Und wo wir gerade bei Google sind. Deren Seite war doch tatsächlich gestern Abend (CH-Zeit) mal nicht erreichbar. Ich hatte das zwar bemerkt, dachte jedoch das Problem läge bei mir. Ist mir dann aber schon komisch vorgekommen, dass zwar google.com, google.co.uk, google.ch und google.de nicht erreichbar waren (und auch ein DNS Resolving auf diese Domains funktionierte bei mir nicht), search.yahoo.com aber schon. Ist interessant, dass eine Site mit 10'000en von Servern doch noch DNS Problemen zum Opfer fallen kann. Wäre jetzt natürlich super zu wissen, was die Ursache dafür war. Immerhin könnte man da einiges davon lernen.
Google Web Accelerator Probleme
GWA hat einen "Prefetch" - grob übersetzt "Vorlader" - eingebaut. Wenn der Benutzer eine Seite lädt, wird GWA verlinkte Seiten gleich auch laden. Dies bewirkt, dass die nächsten Seiten schneller laden, weil sie sich bereits im Cache befinden. Gleichzeitig bewirkt das natürlich auch eine Verfälschung der Statistiken. Es gibt aber noch ein grösseres Problem. Wenn nun auf der Seite beispielsweise ein Logout-Link vorhanden ist, kann es offenbar passieren, dass Google diesen Link anklickt und somit den Benutzer ausloggt.
Das zweite Problem betrifft den Cache, der offenbar bei Seiten mit Login Probleme bereitet. Ist zum Beispiel GWA-Benutzer Karl im gleichen Forum eingeloggt wie GWA-Benutzer Max, kann es vorkommen, dass Max plötzlich als Karl eingeloggt ist und umgekehrt.
Auch scheint die GWA-Webseite schon seit einiger Zeit Probleme zu haben. Bei mir wird momentan das Bild auf der Startseite nicht geladen. Vorher wurde ich auf die Google Toolbar Seite umgeleitet. Wenn es wenigstens 1. April wäre, dann würde ich das alles verstehen...
Einige Referenzen:
Google Web Accelerator
Da gibt es aber etwas anderes, was mich stört: Privatsphäre. Immer wieder habe ich bei dem Thema Privatsphäre & Google Bauchschmerzen. Wieso braucht Google ein globales Cookie, unter welchem alle gelesenen Mails (durch gmail), gesuchten Webseiten (durch google.com), besuchte Webseiten (durch den Accelerator), gesuchte Produkte (durch Froogle, momentan nur US?), gesuchte News (Google News) und all die anderen Dienste miteinander verbunden werden können?
Google weiss heute schon extrem viel über Personen, die Cookies zulassen und nie leeren. Zurück kurz zum Web Accelerator. Google ist so nett eine Privacy Policy anzubieten. Den Inhalt kann man zusammenfassen in "Wir sammeln deine Daten, du musst aber keine persönlichen Informationen angeben". Also ehrlich gesagt, ich bin eher bereit meinen Namen anzugeben, wenn ich explizit danach gefragt werde, als ich meine Surf-History offenlegen möchte!
Verschwörungstheorien rund um Google gibt es übrigens bei der (nicht über alle Zweifeln erhabenen) Google Watch Webseite.
Vollzeit für del.icio.us
After seeing my little project go from a small hobby to a large one and
then consume all my waking hours, I've decided to quit my job and work
on del.icio.us full time.
I've given a lot of thought to how to make this happen, and ultimately
decided that the best way forward is to take on some outside investment.
Ich habe sowieso das Gefühl, dass del.icio.us bald einmal aufgekauft werden könnte, so ganz à la Flickr.
Baslerstab Artikel
Der Artikel beginnt mit einem Aufreisser. Das Thema Sex wird prominent plaziert, war aber bei uns nur am Rande erwähnt.
Einige von ihnen veröffentlichen ihre intimsten Sexerlebnisse, andere publizieren die neusten Trends der Computerwelt. Sie nennen sich «Blogger». Und sie boomen. Vergangenen Samstag trafen sich zum vierten Mal Blogger aus der gesamten Schweiz im «Birseckerhof».
Dann kommt eine kurze Definition, die zu grossen Teilen aus Stefans Weblog FAQ zu kommen scheint:
«Blog» ist die Kurzform von «Weblog». Die Bezeichnung Weblog setzt sich zusammen aus den Wörtern «Web» und «Log». Log kommt von Logbuch und meint eine journalartig geführte Aufzeichnung von Ereignissen. Leute, die ein Weblog betreiben, nennt man Blogger. Den Inhalt seines Blogs bestimmt jeder Blogger selber.
Das Zitat von Andreas, welches die heutige Blog-Entwicklung mit E-Mail von früher vergleich, gefällt mir gut.
14 Blogger hatten den Weg nach Basel gefunden. Um zu fachsimpeln oder einfach nur um einen geselligen Abend zu verbringen. Andreas Jakopec, Initiator des Treffens, zeigte sich mit dem Aufmarsch zufrieden: «Es werden von Mal zu Mal mehr.» So etwas wie eine echte Schweizer Bloggerszene gäbe es aber nicht. «Es ist ein bisschen wie mit den ersten E-Mails vor zehn Jahren, da wurde man auch als ‹Freak› betrachtet, wenn man eine Adresse hatte.»
Nun zum Thema Exhibitionismus, was ja in dem Zusammenhang immer wieder ein Thema ist. Ich habe unter anderem auch erklärt, dass das genau gleiche früher schon bei Webseiten eine Frage war. Schlussendlich entscheide ich aber auf meiner eigenen Webseite (und deszufolge auch auf meinem Weblog) selber, was ich veröffentliche und was nicht. Wir haben darüber diskutiert, dass sich die meisten Weblogger überlegen, was sie veröffentlichen und was nicht. Insbesondere zwei Kriterien sind da wichtig: erstens sollte die Veröffentlichung legal sein und zweitens werden auch oft Dinge nicht veröffentlicht, die in der Zukunft schaden können.
Der folgende Absatz enthält zusätzlich auch ein Zitat von Stefan, welches er auf seinem Weblog nachträglich noch dokumentiert hat.
Doch worin liegt die Motivation, eine anonyme Öffentlichkeit mit privaten Erlebnissen und Gedanken zu beglücken? «Klar, ein bisschen exhibitionistisch ist das schon», erklärt Patrice Neff, «aber längst nicht alle Blogger breiten öffentlich ihr Privatleben aus.» Ein Fachblog zum Beispiel diene vor allem auch zur Sammlung und Weitergabe von Neuigkeiten.
Für viele Blogger ist ihr Blog auch eine Art Ventil. Auf diese Art und Weise können sie ihre Meinung zu den unterschiedlichsten Themen loswerden. «Viele Artikel sind eigentlich nichts anderes als nicht abgeschickte Leserbriefe», weiss Stefan Bucher.
Zwar schreibt der Blogger für eine breite Öffentlichkeit, die Resonanz hält sich hingegen oftmals in Grenzen. Meist sind es die eigenen Freunde oder andere Blogger, die die veröffentlichten Artikel lesen. Hin und wieder erhält man eine Kritik oder Anregung. «Die allermeisten Blogs haben eine Zielgruppe von fünf Personen», so Bucher.
Wer also der Welt etwas mehr oder minder Relevantes mitzuteilen hat und bis heute nicht wusste, wie er das tun soll, der kennt jetzt eine Möglichkeit. Computer anschalten, Weblog eröffnen, losbloggen!
Alles in allem finde ich den Artikel recht gut. Zum Schluss kommt der Tipp, ein Weblog zu eröffnen. Da wäre eine URL noch gut gewesen, wie/wo denn das geht.
Und jetzt bin ich noch gespannt auf den anderen Artikel, welcher in der NZZ veröffentlicht werden soll.
Ach ja, Mark hat einige (drei) schöne Fotos zum Treffen veröffentlicht, unter anderem wie ich den Journalisten irgendwas erkläre (der mit dem grauen Pullover ist offenbar Philipp Schrämmli - jedenfalls war er für den Baslerstab da).
Update 23. März: Der Artikel ist jetzt im Archiv zu finden. Die erste URL war tatsächlich sehr temporär.
Yahoo! kauft Flickr
Und weil wir gerade bei Yahoo! sind. Die werden mir immer sympathischer. Und ich habe irgendwie stark das Gefühl, dass Jeremy, das Yahoo! Search blog, die hin und wieder überarbeiteten Websuche und das Yahoo! Next Labor die Hauptverantwortlichen dafür sind. So ungefähr in der Reihenfolge. Google verwende ich momentan nur noch wegen der Newsgruppen Suche.
Hosting in der Schweiz
Metanet bietet Server Hosting zum Preis von 100 Franken an. Der Server wird gemietet und ist in dem Preis enthalten, 100 Gigabyte Traffic pro Monat sind ebenfalls dabei. Verschiedene Linux Systeme können ausgewählt werden. Zudem gibt es das Angebot Server Housing, bei welchem die Server-Miete nicht inklusive ist. Kostet 77 Franken pro Monat und kommt mit 50 Gigabyte Traffic. Co-location mit 20 Units in einem 19" Rack schliesslich kostet 777 Franken inklusive 2 Mbps Bandbreite.
Bei Init Seven kostet das günstigste Server Housing Angebot 200 Franken. Dabei sind nur 4 Gigabyte Traffic inklusive. Zum Vergleich mit Metanet, wo bei dem Angebot 50 GB Traffic dazugehören: bis zu 40 GB kosten bei Init Seven 500 Franken, danach bis zu 100 GB 800 Franken. Dafür wird hier der 2nd DNS Service mit angeboten, was bei Metanet nochmals extra kostet (und zwar 50 Franken pro 10 Domains laut Email Antwort). Rackspace bei Init Seven kostet für 5 Units und 1 Mbps Bandbreite 333 Franken ohne Mwst.
Nach meiner aktuellen Analyse würde ich mit einem einzelnen Server zu Metanet, ab spätestens drei Servern aber zu Init Seven gehen. Kennt jemand vergleichbare gute Angebote?
del.icio.us
Mit der Verwaltung von Bookmarks setze ich mich schon seit einigen Jahren auseinander. So ist daraus auch mein erstes grösseres Softwareprojekt entstanden, der Bookmark Manager. Dieses Projekt ist eingeschlafen, da ich nicht mehr Visual Basic programmiere und für den Python Port pyBKM kann ich mich irgendwie nicht voll motivieren.
Nun aber nochmals zu del.icio.us. Mit dem Tagging kann ich mich mittlerweile gut anfreunden. In dem Zusammenhang gefällt mir extisp.icio.us ganz gut. Ich überlege mir sogar, so etwas als Startseite festzulegen.
Dann bin ich ein grosser Fan von simplen URLs. Und das ist für mich einer der Hauptvorteile von del.icio.us. Muss mal recherchieren, ob schon jemand einen Artikel zum Thema "Adressleiste als Teil der Benutzeroberfläche" geschrieben hat. Hier eine kurze Zusammenfassung meiner Gedanken, warum sich gute und kurze Adressen lohnen:
- URL Hacking wird möglich: wenn ich auf meiner Bookmark-Liste bin, kann ich schnell meinen Benutzernamen in der URL durch den eines anderen Benutzers ersetzen. Dadurch komme ich schnell zu dessen Bookmarks.
- Direkt-Eingabe von Links wird möglich: es ist so problemlos möglich, kurz meine Bookmarks mit einem bestimmten Tag anzuwählen, ohne erst eine Suchfunktion aufzusuchen.
- History im Browser wird lesbar: ich gebe in der Adressleiste "del" ein und sofort sehe ich die ganzen bisher besuchten URLs bei del.icio.us. Und nun kann ich auch anhand der URL die richtige Seite anwählen, was bei meineseite.com/bookmarks/tags.php?tag=super&sid=dfjskdfhj378_fshdjrrh4r und so weiter nicht annähernd so gut möglich ist.
- Und last but not least: Suchmaschinenoptimierung. Aber darüber wurde schon viel geschrieben.
Und der dritte grosse Pluspunkt, den ich soweit an del.icio.us erkennen kann sind die RSS Feeds. Der RSS Reader ist heute oft, wenn nicht sogar schon fast immer, Ausgangspunkt für meine tägliche Web-Lektüre. Da können auch einige del.icio.us Feeds nicht schaden. Und natürlich lassen sich diese RSS Feeds auch für diverse Hacks "missbrauchen".
Ich habe nun hier im Blog das Delicious Plugin aktiviert. Rechts unter den anderen Links tauchen die 10 zuletzt gebookmarkten Links von mir auf.
Gmail Spooler mit 1.5 Millionen Einladungen
Also, liebe Gmailer. Ihr könnt nun aufhören eure Einladungen bei eBay zu versteigern oder in euren Weblogs und E-Mail Signaturen zu vermarkten.
Google Map: Google enttäuscht mal wieder
So kann ich auch die Aussage vieler Blogger, wie zum Beispiel von Jeremy Zawodny nicht unterschreiben, dass Mapquest nun weg vom Fenster sein soll. Denn Mapquest hat rausgefunden, dass die Welt nicht nur aus den USA besteht. Am einfachsten geht die Suche, wenn man mapquest.de statt .com besucht.
Und für all die Blogger, welche das Google Maps Javascript toll finden. Da bin ich nach wie vor von search.ch's map beeindruckt. Und sehr praktisch ist da die URL-Schnittstelle. Zum Beispiel kann direkt map.search.ch/St.Gallen/Hodlerstrasse 2 eingegeben werden um die Hodlerstrasse 2 in St. Gallen zu finden.
Gmail Einladugen - Gmail bald für alle?
Bis dahin können Einladungen vom gmail invite spooler abgeholt werden. Quasi der Google-Registrations-Dienst. Meine Einladungen gehen nun dort hin.
Magnatune
Alle Lieder dürfen auch vor dem Kauf in guter Qualität als MP3 angehört werden. Die Qualität der Musik ist - soweit ich das beurteilen kann - sehr gut. Als Einstieg empfehle ich die Magnatune Compilations oder der Radio Mix, der für jedes Genre zur Verfügung steht (Link jeweils zuoberst auf der Genre Seite).
Beim Download erhält man die MP3 oder OGG Vorbis Dateien und nicht irgendwelche DRM-geschützten nur-im-mediaplayer oder nur-auf-dem-ipod anhörbaren Stücke.
Noch habe ich nichts gekauft, aber ich denke das geht nicht mehr lange.
Wikinews in der NZZ
Michael schreibt dazu:
Und freilich wird man auch nicht müde, immer wieder die gleiche Kritik anzubringen. Kann man sich auf Texte verlassen, die von “Amateuren” verfasst wurden? So geschehen in einem Beitrag in der Neuen Zürcher Zeitung. Witzigerweise widerlegt sich Stefan Krempl, der Verfasser, im selben Artikel gleich selbst. Dass es um die Wikinews geht, muss man erraten, denn das Wort kommt im Text gar nicht vor. Stattdessen verwechselt Krempl Wikimedia mit den Wikinews.
Sein Fazit:
Es ist wohl kaum denkbar, dass ein derart gravierender Fehler in einem Wiki unbemerkt geblieben wäre. Dagegen kann man davon ausgehen, dass der Beitrag in der Neuen Zürcher Zeitung auch in den nächsten 225 Jahren nicht verbessert wird.
Wo er recht hat, hat er recht. Ich selber bin nicht unbedingt Fan von Wikinews aber aus anderen Gründen als von der NZZ angeführt. Bei Wikipedia werden Artikel oft über längere Zeit gut. Bei News-Artikeln fehlt aber diese Zeit, da es schnell gehen muss. Das Projekt werde ich trotzdem aufmerksam verfolgen.
(Via Stefan Bucher)
rel=nofollow bei Wikipedia
Nachtrag zu rel=nofollow
When the partying half of the blogosphere gets sobers about this, we'll all come to realise what dimensions of the web have been removed. Votes are now restricted to whoever decides the contents of brochureware and other official websites, people with the technical means to be their own webmasters and bloggers. And then only to the opinions expressed in their own living room.
Erstens hat er recht, dass so das Web weniger demokratisch wird. Seine Aussage kann ich entsprechend auch voll unterschreiben. Als kleinen Gegenpunkt kann man nennen, dass es selten leichter war, eine eigene Webseite zu eröffnen - vor allem ein eigenes Weblog ist schnell zu haben.
Laut seiner Aussage hat auch Wikipedia das Attribut für externe Links eingefügt. Und tatsächlich, ein kurzer Check zeigte, dass dem so ist. Und da hört der Spass für mich auf. Klar kann man Wikipedia spammen. Aber die Erfahrung zeigt, dass die Wikipedianer meistens schnell auf Spam reagieren und es rauslöschen, so dass es sich dabei um eines der kleinsten Probleme von Wikipedia handelt. Dass nun aber alle externen Links von Wikipedia nicht mehr zum entsprechenden Pagerank dazuberechnet werden, das schadet der Natur des Webs bzw. vor allem den Suchmaschinen selber ganz erheblich.
Gut möglich, dass sich die Suchmaschinen so selber ins Bein schiessen. (Via Roger)
Kommentar-Spam wird unattraktiver
Google hat gestern Nachmittag (US-Zeit) eine Massnahme angekündigt, welche Kommentar-Spam einiges unattraktiver machen wird. Dem A-Tag wird das Attribut rel="nofollow" angehängt, was bewirkt, dass Suchmaschinen dem Link nicht folgen oder diesen mindestens nicht in die Berechnung des Page Ranks einfliessen lassen. Die momentan für dieses Attribut vorgesehene Werte sehen ein nofollow nicht vor. Aber das Attribut rel existiert im A-Tag bereits, demzufolge sollte diese Erweiterung keine Probleme verursachen. Im Gegenteil, ich begrüsse diese Massnahme.
Eine grosse Zahl von Blog-Anbietern haben bereits ihre Unterstützung zugesagt. Und Yahoo und MSN werden dieses Attribut auch unterstützen. (Via Golem und Heise).
Ruby on Rails
Die letzten Tage habe ich ein wenig mit Ruby on Rails experimentiert. Es handelt sich um ein Framework zur Web-Entwicklung in der Programmiersprache Ruby. Ein Rails Tutorial baut eine Todo Applikation auf eine sehr elegante Art und Weise. Ich hatte beim Lesen dieses Dokumente schon etliche "ja aber" in meinem Kopf, insbesondere von der Sorte was denn passiert, wenn die Applikation etwas komplexer wird.
Nun habe ich eine erste kleine Applikation geschrieben und bin soweit mal sehr begeistert. Alles lief ziemlich einfach und überzeugt mich bis jetzt. Ruby hatte ich bereits früher angeschaut und von da schon als sehr elegante Programmiersprache in Erinnerung. Durch eine Funktion von Ruby on Rails namens Scaffolding ist die Entwicklungszeit für eine Datenbankbasierte Applikation sehr kurz.
Verwendet wird eine sehr saubere MVC Struktur, welche auch eine gute Pflegbarkeit über längere Zeit verspricht.
Ich denke, ich werde damit noch mehr entwickeln und auch durchaus hier mal noch über meine Erfahrungen damit schreiben.
Bess Zensur Proxy
Die Software Bess wird offenbar an vielen US-amerikanischen Schulen und Bibliotheken eingesetzt um Kinder und andere Menschen vor "gefährlichen" Seiten zu schützen. Solche Programme sind, obwohl im Ansatz ja eine gute Idee, immer wieder in Kritik geraten, weil es halt nicht möglich ist, alle Seiten weltweit richtig zu klassifizieren. So wurde ich darauf aufmerksam gemacht, dass meine Bible Wiki in Bess geblockt wird. Da ich mir keines gefährlichen Inhaltes bewusst bin (also keine Pronographie, Hass-Tiraden, Drogen-Themen, Mord, sonstige einschlägige Bilder, etc) bin ich dem mal nachgegangen. Beim Hersteller N2H2 gibt es einen URL checker. Da habe ich dann mal die Web Adresse eingegeben und tatsächlich, die Seite ist gelistet als Web Page Hosting/Free Pages. Die Beschreibung da ist aber reichlich komisch. Es scheint, dass viele Hosting Provider einfach pauschal geblockt werden. Auch meine Seiten patrice.ch, patriceneff.ch oder berin.ch sind da entsprechend gelistet. Und, der Clou, auch eine Seite wie nestle.ch fällt in diese Kategorie.
Naja, so etwas macht diese Software nicht gerade zuverlässiger. Dafür befinde ich mit Nestlé in guter Gesellschaft.
WEB.DE mit unlimitierten Mailboxen
WEB.DE hat seinen Benutzern unlimitierten Speicherplatz spendiert. Nachdem Google mit Gmail ein Gigabyte zur Verfügung gestellt hatte, zogen weltweit verschiedene Freemailer nach.
Jedoch ist dieses Upgrade nur für die WEB.DE Club Mitglieder wirksam, die pro Monat fünf Euro hinblättern. Wie gross die Kapazität für FreeMail Konten ist, habe ich auf die Schnelle nicht entdecken können.
UPDATE 14.12.2004: Habe gerade von Sascha Carlin eine Mail erhalten, wonach der kostenloses WEB.DE Dienst offenbar über 100 MB verfügt.
Blog von Sahlenweidli
Das Sahlenweidli (Aus Gotthelfs Zeiten - ihr wisst schon) hat nun auch ein Weblog. Wenn ich das richtig verstehe bloggen da aber nicht die Einwohner, die im TV vorgeführt werden, sondern echte Landwirte. So heisst es da, ich zitiere:
Als Ergänzung zum "Gotthelfleben" auf dem Sahlenweidli erhielten wir von PRO EMMENTAL den Auftrag, die heutige Landwirtschaft in einem Online-Tagebuch darzustellen.
Na da bin ich ja mal gespannt.
Ungültige Adresseingabe in Firefox geht zu Microsoft
The Inquirer hat entdeckt, dass die Eingabe eine URL mit zwei http:// in Firefox auf Microsoft.com landet. Der Benutzer gibt also zum Beispiel die URL http://http//www.campusplus.com/ ein, und Firefox ruft Microsoft.com auf. maol hat das Thema dann aufgegriffen, kann sich das aber auch nicht ganz erklären.
Eine erste Erklärung ist schnell gefunden, wissen doch Firefox Power User, dass die Eingabe einer nicht gefundenen Adresse in der Adressleiste automatisch zu einer Google "Feel Lucky" Abfrage führt. Das kann sehr praktisch sein. Gibt zum Beispiel ein Anwender "Patrice Neff" in die Adressleiste ein, landet er automatisch auf meiner Webseite.
Die schwierigere Frage ist, wieso ausgerechnet Microsoft.com ausgewählt wird. Eine Abfrage nach zum Beispiel http://http//www.campusplus.com/ bei Google gibt kein Resultat zurück. Mit Hilfe eines Netzwerk-Sniffers, wie zum Beispiel ngrep, lässt sich in Erfahrung bringen, dass Firefox in dem Fall nur nach "http" sucht. Also wird vielleicht alles vor dem ersten Sonderzeichen verwendet oder ähnlich. Eine Google Suche in verschiedenen Ländern nach "http" zeigt dann folgende Seiten als jeweils erstes Ergebnis:
- google.com: microsoft.com
- google.ch: spiegel.de
- google.de: spiegel.de
- google.fr: Le Monde
- google.co.uk: microsoft.com
- google.co.jp: Asahi (japanische Zeitung)
Das erklärt auch die von Inquirer Lesern registrierte unterschiedliche Verhaltensweise in verschiedenen Ländern. Die Sprachversionen haben meines Wissens auch den entsprechenden Link zu Google eingebaut.
Also, bitte ja nicht wieder zu einem Skandal hochschaukeln, wie das bei den Ebay Links in der deutschen Firefox passiert ist. Immer schön auf dem Boden bleiben und nicht überall eine Verschwörung der ganzen Welt vermuten lautet die Devise.
Firefox Extension für Wikipedia
Michael Keppler hat für den Firefox Browser eine Wikipedia Extension entwickelt. Diese stellt in dem Textfeld ein Kontextmenü mit nützlichen Funktionen zur Verfügung. Bei mir funktionieren momentan leider die Shortcuts noch nicht. Denn Ctrl+Shift+B für fett ist schon gemütlicher als sechs mal das einfache Anführungszeichen einzugeben (je drei vor unter hinter dem einzufettenden Text).
Download der Extension. Der Text auf der Seite tönt aber so, als wäre diese nur temporär. Der Link ist also evtl. bald tot.
Google an die Weltherrschaft!
the Inquirer weiss um die neuen Produkte von Google, welche Googles Weltherrschaft sichern sollten.
Derweil rege ich mich immer wieder über Google auf. Ich meine, es kann doch nicht angehen, dass eine Suche bei Google nach Busen auf der ersten Seite auf meinen Weblog Artikel zum Thema Benutzer wissen mehr über Janet Jacksons Busen als über Viren verweist. Eine Zeitlang war ich mit diesem Suchbegriff sogar auf Platz zwei. Direkt nach dem Blick.
Yahoo News relaunch
Yahoo Search gefällt mir je länger je mehr. Gerade auch die Beta-Version von My Yahoo Search. Ähnlich wie A9 ist es hier möglich, die Suche zu personalisieren. Konkret bedeutet das, dass vergangene Suchresultate eingesehen oder auch Seiten aus den Suchresultaten geblockt werden können.
Nun hat Yahoo die News-Suche überarbeitet. Einige Infos dazu hat Jacob Rosenberg nun auf dem Yahoo Search Blog gepostet.
Nochmals ein Trackback Test
Michael hat mich gebeten, nochmals einen Trackback zu versuchen. Hiermit also ein Link auf seine Entwicklungsumgebung.
Mal schauen, ob das dieses mal funktioniert.
StumbleUpon
Habe heute StumbleUpon zum ersten mal ausprobiert und es scheint mir eine sehr interessante Idee zu sein.
Die grobe Idee ist es, Benutzern die Bewertung von Seiten zu erlauben. Über den Knopf "Stumble!" (englisch für "stolpern") kann der Benutzer interessante Seiten. Bei der Auswahl von möglichen Seiten beherzigt die Software einerseits eingegebene Interessen, andererseits aber auch die bewerteten Seiten.
Bin jetzt so bereits auf einige interessanten Seiten gestossen. Ach ja, natürlich mit Firefox Extension.
Google Suche per SMS
Wie Golem berichtet, kann man in den USA ab sofort bei Google über SMS suchen. Erste Reaktion war, "wofür braucht man das", aber der Artikel klärt über die Vorteile auf. Eine Websuche bringt ja wirklich nichts, aber die Möglichkeiten von Preissuche, Firmenanfragen (Restaurant zum Beispiel) oder Wörterbuch machen Sinn.
Für mich eine Killerapplikation von SMS ist die Fahrplanauskunft der SBB, also glaube ich sehr wohl an die Nützlichkeit solcher Dienste.
Furl wird von Looksmart übernommen
Furl ist ein interessanter Dienst, Webseiten zu archivieren. Sehr nützlich, wenn man eine gute Seite sieht, und sicher stellen möchte, dass man auf diese auch nächsten Monat oder nächstes Jahr Zugriff hat. Zum Beispiel für Dokumentationen, nützliche Tipps, etc. Kann so auch als Ersatz für Bookmarks dienen.
Diese Seite wurde nun von LookSmart übernommen. Das ist offenbar noch nicht offiziell bekannt gegeben sondern wurde erst den Mitgliedern per E-Mail mitgeteilt. Nebeneffekt des Kaufs: der Platz für die Benutzer wird auf 5 Gigabyte pro Person erhöht.
Internet Explorer stürzt ab - durch CSS
Eric Meyer hat im Internet Explorer ein ungewöhnliches Problem entdeckt. Durch die Angabe von speziellen CSS-Angaben, ist es möglich, den IE zum Absturz zu bewegen. Leider konnte die genaue Ursache noch nicht ermittelt werden, doch scheint es etwas mit floats zu tun zu haben.
Dies ist der ideale Zeitpunkt, darauf hinzuweisen, dass niemand mehr Internet Explorer verwenden muss. Es gibt bessere Browser, die nur darauf warten von dir herunter geladen zu werden. Der momentan von vielen unabhängigen Medien (zum Beispiel BusinessWeek, Wall Street Journal, c|net, Forbes) empfohlene Browser ist Firefox. In nur zehn Tagen wurde dieser über eine Million mal herunter geladen. Und zum ersten mal seit Jahren verliert der Internet Explorer wieder Martkanteile. Also, nichts wie los, hol dir Firefox! Aktuelle News gibt es bei der Spread Firefox Kampagne.
Blogtest root@herzog-it.de
Über das blogg.de Blogverzeichnis gerade auf das Weblog von Michael Herzog gestossen. Da er um einen Trackback bittet, versuche ich das gleich mal mit meiner Blosxom Installation. Und dazu gleich noch ein wenig Feedback an dich, lieber Michael:
- Ich sehe da keine verlinkten Permalinks. Bitte zum Beispiel den Titel oder einen Text "Permalink" direkt verlinken. Ohne das wird niemand ein Trackback setzen (ich musste die URL selber raus suchen und zusammen flicken).
- Der Kontrast der Seite ist extrem niedrig. Das graue sollte dunkler sein, vor allem wenn es Text und nicht einfach Verzierung ist.
- Zu dem Rootserver (auch wenn es bereits zu spät ist): ich habe meine Kiste bei Bytemark stehen und bin bis jetzt extrem zufrieden mit dem Angebot.
Also, ich hoffe, das funktioniert auch alles.
UPDATE 20.09.2004: Ne, funktioniert gar nichts. Im Quellcode keine RDF-Tags mit Trackback
Browsercam
Ich arbeite gerade an einer neuen Seite für Frontiers. Da ist mir Browser Cam über den Weg gelaufen. Das ist ein sehr cooles Tool, um die erstellte Webseite in verschiedenen Browsern zu testen. So habe ich die Möglichkeit, mein Design mal ohne grossen Aufwand in verschiedensten Browsern unter Linux, Windows und Mac zu testen.
Dazu gibt es zwei verschiedene Möglichkeiten. Erstens kann man automatisiert pro Plattform je einen Screenshot erstellen lassen. Zweitens kann man sich per VNC verbinden und so auch dynamische Features wie zum Beispiel Rollovers testen. Für ersteres gibt es sogar eine kostenlose Test-Version. Einfach auf der Startseite registrieren und los gehts.
More Eric Meyer on CSS
Gestern ist mir beim Buchhändler das Buch More Eric Meyer on CSS aufgefallen. Kurz darin geschnuppert und dann gekauft. Das Buch bringt viele Tipps und Tricks zu CSS, geschrieben vom anerkannten Experten Eric Meyer.
In 10 Projekten beschreibt Eric Schritt für Schritt, wie CSS in der Praxis eingesetzt wird. Der Leser wird dabei ermutigt, die Schritte auf dem eigenen Rechner nachzuvollziehen. Immer wieder wird auch erklärt, wieso etwas genau auf diese Art gelöst wird und so zum Beispiel auf schwierige Elemente der CSS Spezifikation oder Fehler des Internet Explorers hingewiesen.
Das Buch sieht sehr empfehlenswert aus. Ich habe das Buch bis jetzt aber nur einmal von vorne bis hinten durchgelesen und die Beispiele noch nicht selber nachvollzogen. Doch bereits dabei habe ich einiges neues über CSS gelernt.
Kaufen kann man das Buch zum Beispiel bei Amazon oder buch.de. Die Schweizer online-Händler Orell Füssli und buch.ch haben das Buch leider noch nicht im Angebot.
Blog Ping Dienste = DDOS?
Damit ein paar Leute die ganzen Artikel hier sehen, dachte ich, ich könnte da mal ein ping einbauen. Habe dann auch die Seite Pingomatic gefunden, welche gleich mehrere andere Dienste anpingt. Habe dann nach dem ersten Post gemerkt, dass ein Tag im Header eine gute Sache wäre, damit diese Dienste auch den Feed am richtigen Ort saugen. Doch nun laufen die ganzen Dieste Amok.
Erstens saugen sie die ganze Zeit irgendwelche nicht existierende Feeds. Die hängen einfach überall mal rss.xml, atom.xml, index.rdf, und andere an. Und dann scheinen sie das noch voneinander zu kopieren. Wenn der Technoratibot mal vorbei kommt, kann ich sicher sein, dass ein paar Sekunden später auch noch der blogg.de Crawler neugierig wird.
Hat da ein erfahrener Weblogger als ich es bin einen Rat für mich? Erstens, wie stelle ich diese ganzen unsinnigen Aufrufe ab und zweitens wie mache ich es nächstes mal besser?
UPDATE 18.08.2004: Mittlerweile scheinen sich die wieder einigermassen beruhigt zu haben. Aber mein Eindruck ist, dass man nach einem Ping erstmal eine ganze Weile die ganzen Crawler auf seiner Seite findet. Dabei wäre der Ping doch genau dazu gedacht, zu viel Traffic zu vermeiden?
UPDATE 18.08.2004: Ja, das mit dem DDOS (Distributed Denial of Service) ist ein bisschen drastisch formuliert für einige HTTP GET Abfragen die sich im Rahmen von weniger als einer Anfrage pro Sekunde bewegen.
BugMeNot.com down
BugMeNot, eine super Seite um die obligatorische Registrierung vieler Seiten zu umgehen, scheint einem Konfigurationsfehler zum Opfer gefallen zu sein. Hoffentlich aber bald wieder zurück.
UPDATE 19.08.2004: Es scheint sich nicht einfach nur um einen Konfigurationsfehler zu handeln. Was ich erst nicht wahrhaben wollte, könnte jetzt wirklichkeit werden. Auch an anderen Orten wird über das Verschwinden von BugMeNot gesprochen. Was wohl der Grund sein könnte? Boing Boing wettet, dass Anwälte im Spiel waren.
UPDATE 20.08.2004: Juhui, BugMeNot.com ist wieder zurück. Habe keine Info gefunden, wieso das down war. Auch bei Technorati finden sich keine Infos aus anderen Blogs.